基于Selenium的网络爬虫。
Background 突然需要一个爬虫爬取一个页面上的部分信息,但是我没有很高深的有关爬虫,html,js 方面的技术和知识,只知道获取网页源码使用正则表达式匹配这样的基本原理,遇到使用 js 动态生成元素的网页就没法爬了。
但是使用Selenium即使是对 js 之类的技术一窍不通的小白也可以很迅速的爬取任何在网页上能看到的东西,而且不仅仅能爬取,它还能模拟点击按钮,滑动等操作,以获取更多信息。
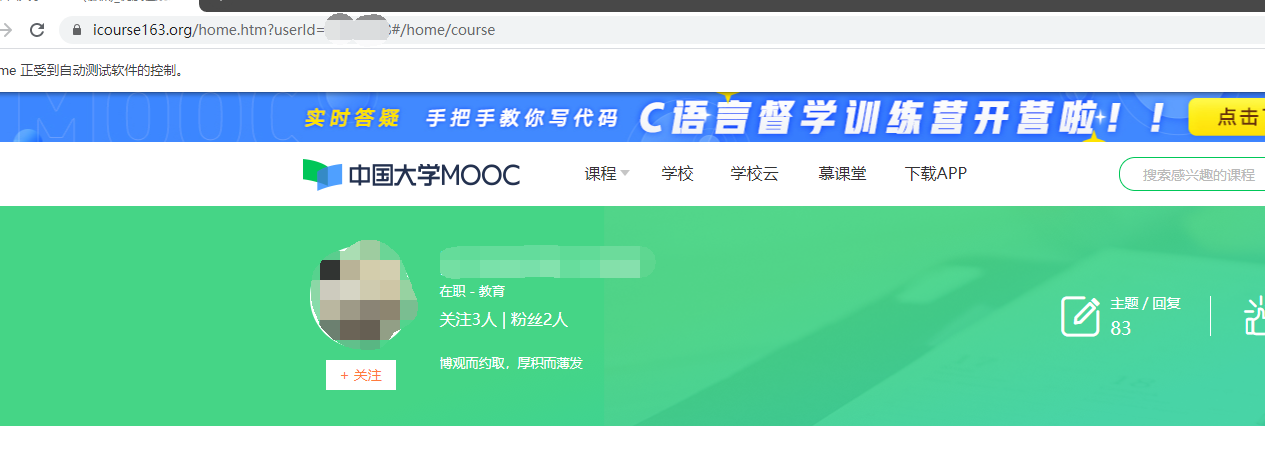
需要爬的是慕课网的用户信息,url 长这样
https://www.icourse163.org/home.htm?userId={id}#/home/course
其中括号里的id是每个用户的id,已经有一个包含所有需要爬取用户id的列表,到时候可以遍历。
需要获取的是网页中这些元素:
马赛克模糊的地方是用户名。
目标是遍历id列表,记录每个列表里用户的用户名,职业,主题,获赞,学习时长等信息。
完整代码在最后。
Step1 启动浏览器 首先是基本思路,Selenium是网页自动测试的工具,在本地使用的时候会真的打开一个浏览器在上面操作,如果是在colab或在无图形界面的服务器上操作可以设置为headless模式。
通常的教程会让你去下载Selenium对应的浏览器driver,由于浏览器版本经常升级,每次都去下就很麻烦,因此这里使用了一个名为
webdriver_manager 的模块,可以自动安装匹配的driver, 运行这段代码,就会自动打开一个空白的chrome浏览器,并转到制定的url。
1 2 3 4 5 from selenium import webdriverfrom webdriver_manager.chrome import ChromeDriverManagerdriver = webdriver.Chrome(ChromeDriverManager().install()) driver.get(f"https://www.icourse163.org/home.htm?userId={id} #/home/course" )
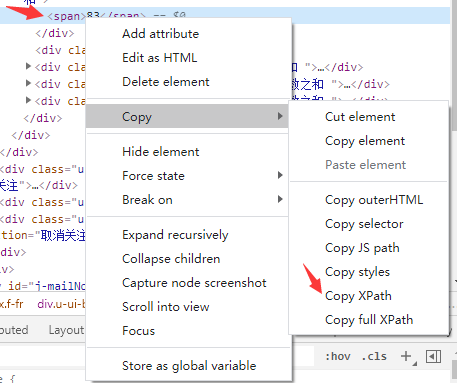
Step2 定位元素 我们的目标是爬取任何看到的又想要的东西,这里我选择使用xpath进行定位,具体方法是按f12 打开开发者工具中的Element面板,按下ctrl + shift + c,进入选择模式,点击想要的那个元素,比如这里我们点击“主题/回复”的数字,于是右侧的Element面板中该数字所在位置就被标识了出来,此时右键它,选择Copy->Copy Xpath 以获取该元素的Xpath进行定位。
得到的Xpath长这样
//*[@id=”j-self-content”]/div/div[5]/div/div/div[7]/span
Step3 获取元素 得到了Xpath,我们就可以获取到该元素中的值,代码长这样
1 2 3 Xpath = '//*[@id="j-self-content"]/div/div[5]/div/div/div[7]/span' item = driver.find_elements_by_xpath(Xpath) text = item[0 ].text
但是这里有一个问题,由于Selenium是模拟操作浏览器以爬取信息,因此页面没加载好的时候很容易出现爬不到东西的情况,因此需要等它爬到东西后才能心满意足的进行下一步,所以这里写个函数来表达这个逻辑。
1 2 3 4 5 6 7 8 9 10 def get_element (Xpath) : text = '' count = 0 while text == '' : item = driver.find_elements_by_xpath(Xpath) text = item[0 ].text count += 1 if count >= 10000 : return 'null' return text
如果一直拿不到东西,那就等着,直到拿到了或者尝试太多次了。
Step4 完整代码 完整代码里包含了两种等待机制, 都是为了防止页面没加载好导致获取不了想要的东西。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 from selenium import webdriverfrom webdriver_manager.chrome import ChromeDriverManagerfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECimport pandas as pddriver = webdriver.Chrome(ChromeDriverManager().install()) name_list = [] id_list = [10030774 , 1003203 , 1003438 , 10034555 , 10037678 , 10037679 ] def get_element (Xpath) : text = '' count = 0 while text == '' : item = driver.find_elements_by_xpath(Xpath) text = item[0 ].text count += 1 if count >= 10000 : return 'null' return text Xpath_dict = { 'name' : '//*[@id="j-self-content"]/div/div[2]/span' , 'job' : '//*[@id="j-self-content"]/div/div[3]/span' , 'topic' : '//*[@id="j-self-content"]/div/div[5]/div/div/div[7]/span' , 'like' : '//*[@id="j-self-content"]/div/div[5]/div/div/div[11]/span' , 'study_time' : '//*[@id="j-self-content"]/div/div[5]/div/div/div[3]/span' , } res_list = [] for id in id_list: driver.get(f"https://www.icourse163.org/home.htm?userId={id} #/home/course" ) driver.implicitly_wait(10 ) locator = (By.XPATH, '//*[@id="j-self-content"]/div/div[2]/span' ) WebDriverWait(driver, 20 , 0.5 ).until(EC.presence_of_element_located(locator)) name = get_element(Xpath_dict['name' ]) job = get_element((Xpath_dict['job' ])) topic = get_element((Xpath_dict['topic' ])) like = get_element((Xpath_dict['like' ])) study_time = get_element((Xpath_dict['study_time' ])) res_dict = { 'id' : id, 'name' : name, 'job' : job, 'topic' : topic, 'like' : like, 'study_time' : study_time, } print(res_dict) res_list.append(res_dict) res_df = pd.DataFrame(res_list) print(res_df)